
How to Create Event-Driven System Templates Using Strimzi
- Guy Menahem

- Feb 12, 2024
- 3 min read

The demand for seamlessly handling and processing large amounts of data in real-time or near-real-time has become paramount, because data data-driven designs are now part of almost every system.
The most vanilla use case is to get data from different sources, process it, and save it to multiple targets. One of the most common and useful tools to stream data is Kafka. Apache Kafka is a distributed streaming platform that enables the building of real-time data pipelines and streaming applications.
In this blog post, I'm going to show you how to easily create event-driven service templates with Kafka using Strimzi.

You Gotta Move Like Data
As with any other stateful application, running Kafka on Kubernetes can become a real pain, especially at scale. What makes it especially challenging is that:
Running Kafka on Kubernetes requires resources for management and operations.
Kafka resources should be defined in git, and not managed with a bunch of scripts. To make this happen we need high expertise in Kafka and a lot of effort.
Creating consumer services requires a deep understanding of events streaming at scale (autoscaling, failure handling, etc.) which requires high development standards.
Why Strimzi?

Strimzi is an open-source project designed to simplify the deployment, management, and operational aspects of Apache Kafka on Kubernetes. It provides operators and components to orchestrate and automate the deployment of Kafka clusters in a Kubernetes environment.
“Strimzi allows us to send hundreds of millions per day into production. It has significantly improved data pipeline delivery time and integrates seamlessly with our cloud-native stack. It meets our need to connect a large number of data systems with a high level of scalability, security and reliability.” – Thomas Dangleterre, Software Engineer @Decathlon
Why Now?
Strimzi advancing into the incubation stage means that the CNCF acknowledges that the project is stable, widely adopted, and with the correct focus, will likely grow to become a graduated project. You can read all the nitty gritty in the CNCF's announcement.
While some people might dread deploying open-source software in enterprise production because it could be abandoned in the future, this decision by the CNCF sets clear expectations for the project's lifecycle.
How Does Strimzi Work?
Strimzi is an operator you deploy on your Kubernetes clusters and it creates and manages the Kafka resources for you.
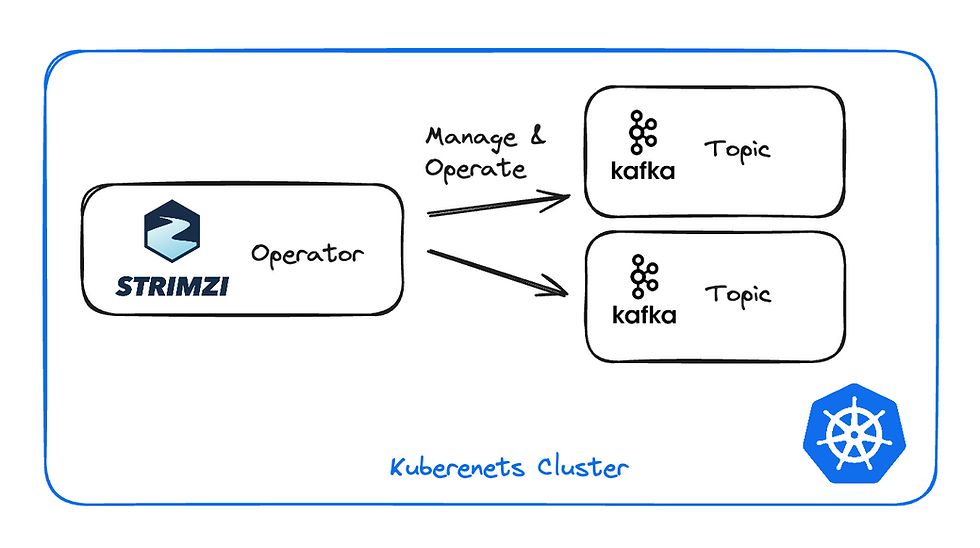
You basically need to define your custom resource and Strimzi will deploy your required configuration. For example, if you need a Kafka cluster, you define it as a CRD and Strimzi will create the Zookeeper & Kafka clusters with the desired configuration you requested.

How to create Strimzi Templates?
The Strimzi operator creates the resources based on CRDs. It allows us to utilize them and create templates for Kafka resources as if they were Kubernetes resources.
Let's take a look at this Helm template and define all the resources we need to run a small event-driven system:

To get an application up and running, a user can define only basic values such as:
Names
Source
Target
We can take that to the extreme and extend it into bootstrapping a simple app, that based on provided values, will connect everything for the user. For example:

How to Deploy Strimzi?
1. Install Strimzi Helm Chart
helm repo add strimzi https://strimzi.io/charts/helm repo updatehelm install strimzi strimzi/strimzi-kafka-operator -n strimzi --create-namespace2. Deploy user first Kafka cluster using Strimzi
kubectl apply -f - << EOF
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: my-cluster
namespace: strimzi
spec:
kafka:
version: 3.6.1
replicas: 3
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: tls
port: 9093
type: internal
tls: true
config:
offsets.topic.replication.factor: 3
transaction.state.log.replication.factor: 3
transaction.state.log.min.isr: 1
default.replication.factor: 3
min.insync.replicas: 1
inter.broker.protocol.version: "3.3"
storage:
type: ephemeral
zookeeper:
replicas: 3
storage:
type: ephemeral
entityOperator:
topicOperator: {}
userOperator: {}
EOF3. Create a Kafka topic
kubectl apply -f - << EOF
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaTopic
metadata:
name: samples
namespace: strimzi
labels:
strimzi.io/cluster: my-cluster
spec:
partitions: 3
replicas: 1
EOF4. Create a producer
kubectl apply -f - << EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-producer
labels:
app: kafka-producer
spec:
replicas: 1
selector:
matchLabels:
app: kafka-producer
template:
metadata:
labels:
app: kafka-producer
spec:
containers:
- name: kafka-producer
image: bitnami/kafka:3.1.0
command:
- "/bin/sh"
- "-c"
- >
kafka-consumer-groups.sh --bootstrap-server my-cluster-kafka-brokers.strimzi.svc.cluster.local:9092 --group my-kafka-consumer-group --topic samples --execute --reset-offsets --to-earliest;
while true; do
echo "YourEventPayload" | kafka-console-producer.sh --topic samples --bootstrap-server my-cluster-kafka-brokers.strimzi.svc.cluster.local:9092 --producer-property linger.ms=1 --producer-property batch.size=65536;
kafka-consumer-groups.sh --bootstrap-server my-cluster-kafka-brokers.strimzi.svc.cluster.local:9092 --group my-kafka-consumer-group --describe;
done
EOFConclusion
I hope you found this short guide useful. My goal was to give you an idea of how you can use Strimzi to save time and effort, and possibly to get you as excited about the project as I am. Personally I hope to see it grow more and I encourage you to contribute.
Stay tuned for more open-source news.



Comments